









 导航分类
导航分类分支机构动态
分支机构动态丨生态环境大模型应用评估基准测试(ELLE)第1赛季结果发布:12款模型谁更“懂”环境?
近日,中国环境科学学会生态环境人工智能专委会发布生态环境大模型应用评估基准测试(Environmental large language model Evaluation, ELLE)第1赛季结果。2025年3月28日-4月3日期间,ELLE对12款主流大语言模型及应用的生态环境专业能力进行多维度测评。测评覆盖污染治理、政策分析等核心场景,最终结果显示:TianGong-Agent-2025-04-01以综合94.3分领跑榜单,紧随其后的DeepSeek-reasoner(93.8分)、ChatGPT-4o-2024-11-20(91.7分)与ChatGPT-o1-2024-12-17(91.0分)展现出头部模型的技术优势,其余模型得分集中在80-90分区间,点击访问完整测评结果:生态环境大模型测试(ELLE)排名。

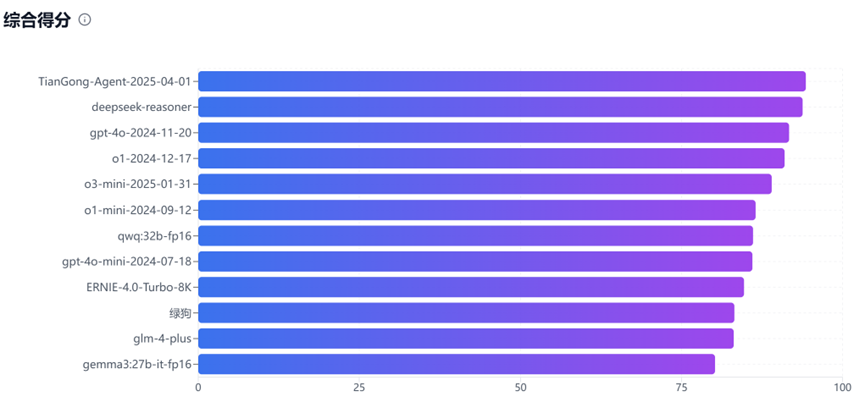
12款主流大语言模型ELLE综合得分排名
本次测试包括多领域、多难度的生态环境专业题目,旨在考察大模型在专业计算、逻辑推理以及政策分析等多方面的综合能力。
计算题(约35%)。涉及公式推导、浓度换算、工程参数计算等,如溶解氧浓度计算、污泥体积缩减以及燃料燃烧的理论空气量计算。
逻辑推理题(约30%)。要求对污染物特征匹配、环境机制分析或治理策略选择,如分析光化学烟雾前体匹配、水质模型选择等。
专业基础知识题(约25%)。涉及环境现象解释、技术原理或政策影响,如生物吸附剂在重金属治理中的原理、碳泄漏机制及其国际贸易影响。
混合类型(约10%)。结合了计算与逻辑推理,典型案例如健康风险评估中日均暴露量公式的推导与应用。
此次TianGong-Agent-2025-04-01智能体架构(https://github.com/linancn/tiangong-ai-langgraph-server)凭借其智能协作框架在评测中表现突出。该架构设计了一套“问题分类→专业化处理→评估迭代”的三阶段问题解决流程。大语言模型首先对问题进行分类,随后将问题分配至相应的处理模块。在这一环节,智能体针对不同类型问题可以灵活调用相应工具,包括自动检索知识库,从而更高效、准确地实现复杂问题的动态处理。在得到初步答案后,智能体不会直接输出初步结果,而是进入评估环节,通过多维度评分体系对答案质量进行客观评价,并提出具体改进建议。若评分未达到预设阈值,问题将重新进入分类环节,形成闭环优化机制,确保最终输出的质量和可靠性。此外,相较于上一赛季,TianGong-Agent在部分环节使用了推理模型。通过以上策略,使TianGong-Agent能够像专业人士一样处理复杂问题,识别需求、调用专业工具、评估反思并持续改进,显著提高了问题解决的准确性,实现比原生大语言模型更优的领域专业性。
随着领域数据的不断补充,大语言模型及其应用在生态环境领域的学科专业度、应用广度与解题深度方面都有望迎来进一步的提升。我们诚挚欢迎更多研究者与开发者参与到ELLE基准测试工作中,共同推动AI在绿色发展和生态文明建设中发挥更加积极的作用。


供稿丨中国环境科学学会生态环境人工智能专业委员会



